Unidad 2 Arquitectura del Gestor.
2.1 Características del DBMS.
Los sistemas de administración de bases de datos son usados para:
- Permitir a los usuarios
acceder y manipular la base de datos proveyendo métodos para construir sistemas
de procesamiento de datos para aplicaciones que requieran acceso a los datos.
- Proveer a los administradores las herramientas que les permitan ejecutar tareas de mantenimiento y administración de los datos.
Control de la redundancia de datos: Este consiste en lograr una mínima cantidad de espacio de almacenamiento para almacenar los datos evitando la duplicación de la información. De esta manera se logran ahorros en el tiempo de procesamiento de la información, se tendrán menos inconsistencias, menores costos operativos y hará el mantenimiento más fácil.
Compartimiento de datos: Una de las principales características de las bases de datos, es que los datos pueden ser compartidos entre muchos usuarios simultáneamente, proveyendo, de esta manera, máxima eficiencia.
Mantenimiento de la integridad: La integridad de los datos es la que garantiza la precisión o exactitud de la información contenida en una base de datos. Los datos interrelacionados deben siempre representar información correcta a los usuarios.
Soporte para control de transacciones y recuperación de fallas: Se conoce como transacción toda operación que se haga sobre la base de datos. Las transacciones deben por lo tanto ser controladas de manera que no alteren la integridad de la base de datos. La recuperación de fallas tiene que ver con la capacidad de un sistema DBMS de recuperar la información que se haya perdido durante una falla en el software o en el hardware.
Independencia de los datos: En las aplicaciones basadas en archivos, el programa de aplicación debe conocer tanto la organización de los datos como las técnicas que el permiten acceder a los datos. En los sistemas DBMS los programas de aplicación no necesitan conocer la organización de los datos en el disco duro. Este totalmente independiente de ello.
Seguridad: La disponibilidad de los datos puede ser restringida a ciertos usuarios. Según los privilegios que posea cada usuario de la base de datos, podrá acceder a mayor información que otros.
Velocidad: Los sistemas DBMS modernos poseen altas velocidades de respuesta y proceso.
Independencia del hardware: La mayoría de los sistemas DBMS están disponibles para ser instalados en múltiples plataformas de hardware.
2.1.1 Estructura de memoria y procesos de la instancia.
Arquitectura de un manejador de bases de datos (DBMS).
Una base de datos en ejecución consta de 3 cosas:
1.- Archivos
2.- memoria
3.- Procesos
Archivos.
- Control (ctl): almacenan información acerca de la estructura de archivos de la base.
- Rollback (rbs): cuando se modifica el valor de alguna tupla en una transacción, los valores nuevos y anteriores se almacenan en un archivo, de modo que si ocurre algún error, se puede regresar (rollback) a un estado anterior.
- Redo (rdo): bitácora de toda transacción, en muchos dbms incluye todo tipo de consulta incluyendo aquellas que no modifican los datos.
- Datos (dbf): el tipo más común, almacena la información que es accesada en la base de datos.
- Indices (dbf) (dbi): archivos hermanos de los datos para acceso rápido.
- Temp (tmp): localidades en disco dedicadas a operaciones de ordenamiento o alguna actividad particular que requiera espacio temporal adicional.
Memoria.
- Shared Global Area (SGA): es el área más grande de memoria y quizás el más importante.
- Shared Pool: es una caché que mejora el rendimiento ya que almacena parte del diccionario de datos y el parsing de algunas consultas en SQL.
- Redo Log Buffer: contiene un registro de todas las transacciones dentro de la base, las cuales se almacenan en el respectivo archivo de Redo y en caso de siniestro se vuelven a ejecutar aquellos cambios que aún no se hayan reflejado en el archivo de datos (commit).
- Large Pool: espacio adicional, generalmente usado en casos de multithreading y esclavos de I/O.
- Java Pool: usado principalmente para almacenar objetos Java.
Procesos.
Threading.
- System Monitor: despierta periódicamente y realiza algunas actividades entre las que se encuentran la recuperación de errores, recuperación de espacio libre en tablespaces y en segmentos temporales.
- Process Monitor: limpia aquellos procesos que el usuario termina de manera anormal, verificando consistencias, liberación de recursos, bloqueos.
- Database Writer: escribe bloques de datos modificados del buffer al disco, aquellas transacciones que llegan a un estado de commit.
- Log Writer: escribe todo lo que se encuentra en el redo log buffer hacia el redo file.
- Checkpoint: sincroniza todo lo que se tenga en memoria, con sus correspondientes archivos en disco.
Tipos de instancias de un DBMS.
Online Transaction Processing (OLTP): compra/venta, telemarketing
* Segmentos cortos de rollback
* Shared Pool muy largo
* Redo log suficiente
* Indices en discos separados
* Segmentos temporales pequeños
Decision Support Systems (DSS): datawarehouse* Segmentos largos de rollback
* Shared Pool relativamente corto
* Redo log suficiente
* Indices apropiados
* Segmentos largos de temporal
* Parallel Query en la medida de lo posible (si está disponible)

La arquitectura de un SGBD hace referencia al modelo interno de funcionamiento del sistema. Es decir a las estructuras internas/físicas que proporciona para el almacenamiento y su relación con las estructuras lógicas/conceptuales. Como es lógico, cada SGBD propone diferentes arquitecturas.
Estructuras lógicas de la base de datos.
En todas las bases de datos relacionales disponemos de estas estructuras lógicas para organizar la información:
- Tablas. Compuestas de filas y columnas en las que se almacenan los datos relevantes de cada base de datos. La mayoría de SGBD usan distintos tipos de tablas, pero en general cuando se habla de tablas se habla del elemento lógico encargado de almacenar los datos.
- Restricciones. Se definen al crear las tablas, pero se almacenan aparte. Están disponibles en el diccionario de datos y marcan las reglas que han de cumplir los datos para que se consideren válidos.
- Índices. Se trata de una lista ordenada de claves que permite acceder a los valores de una o más columnas de una tabla de forma veloz.
- Vistas. Son consultas almacenadas que nos permiten mostrar de forma personalizada los datos de una o varias tablas.
- Procedimientos y funciones. Código del lenguaje procedimental de la base de datos utilizado para ejecutar acciones sobre las tablas (incluidos los triggers).
Estructuras físicas e internas de la base de datos.
Al final todos los elementos lógicos se deben almacenar en archivos cuyo tamaño, dirección,... etc. debe de ser controlado por el DBA. En los distintos tipos de SGBD hay variaciones sobre las estructuras lógicas, en el caso de las físicas su diferencia puede ser total, lo que obliga a conocer muy bien la parte interna del sistema concreto que estemos utilizando.
Las estructuras internas permiten analizar un nivel intermedio entre estructuras lógicas (como las tablas) y las físicas (como los archivos). Por ejemplo, Oracle proporciona espacios de tabla o tablespaces para aglutinar distintos elementos lógicos con distintos elementos físicos a fin de optimizar el rendimiento de la base de datos.
Instancias de bases de datos.
Los usuarios que deseen conectarse a una base de datos, se conectan a lo que se conoce como la instancia de la base de datos (del inglés instance).
En el modo más sencillo de trabajo, el usuario dispone de un software en su máquina local, por lo que se encuentra en el lado del cliente, capaz de conectar con el SGBD. En ese momento se lanza un proceso de usuario. Ese proceso deberá comunicarse (a través de las redes apropiadas) con el proceso de servidor, un programa lanzado en el lado del servidor que está permanentemente en ejecución.
El proceso de servidor comunica a su vez con la instancia de la base de datos, otro proceso en ejecución a través del cual se accede a la base de datos.
 En el caso de bases de datos distribuidas, habrá varias instancias de base de datos con capacidad de atender concurrentemente más usuarios.
En el caso de bases de datos distribuidas, habrá varias instancias de base de datos con capacidad de atender concurrentemente más usuarios. 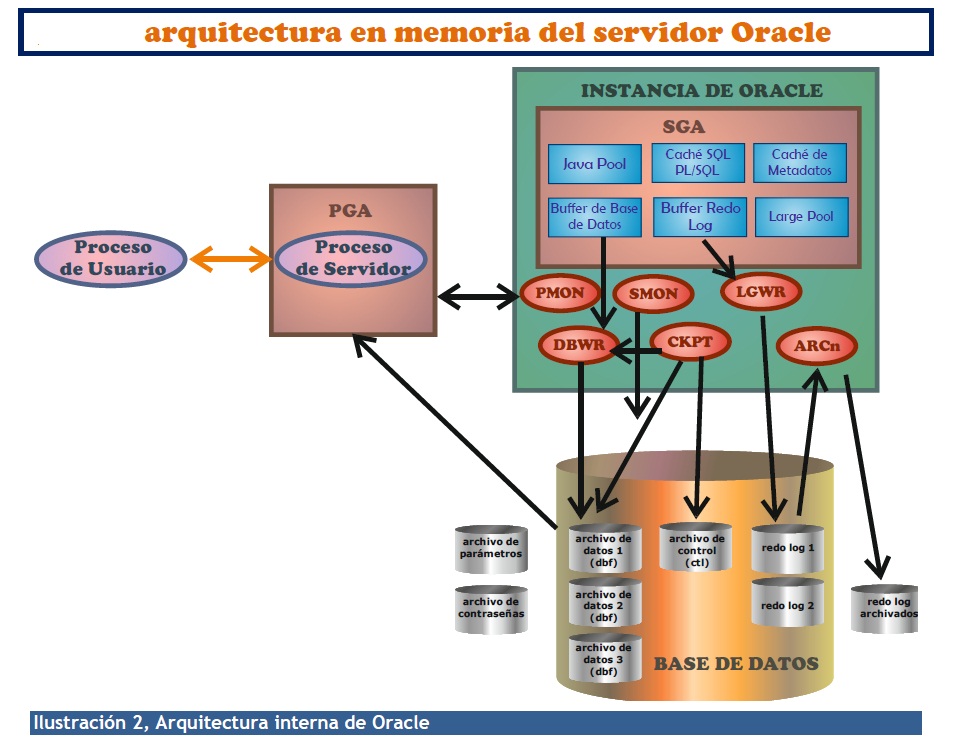
Instancia de Oracle.
Es el conjunto de procesos del servidor que permiten el acceso a la base de datos. Es un conjunto de estructuras de datos y procesos en memoria. Está formado por:
SGA. Area global de sistema. Se trata de la zona de memoria común para todos los procesos de servidor, contien las siguientes estructuras de datos fundamentales:
- Buffer de caché de base de datos. Almacena bloques de datos leídos de la base de datos a fin de que las próximas consultas no necesiten acudir a disco y se las pueda servir de estos datos en la caché.
- Buffer redo log. Estructura que almacena los datos anteriores y posteriores a cada instrucción y así facilitar tanto su anulación, como su realización en caso de problemas.
- Large pool. Área de la memoria que proporciona espacio para los datos necesarios para realizar operaciones de backup y restauración, así como los datos de sesión y otros que permitan aliviar el trabajo de la instancia.
- Shared pool. Consta de la caché del diccionario de datos y de la caché de instrucciones SQL, PL/SQL. De esa forma se acelera la ejecución de consultas e instrucciones que utilicen los mismos metadatos o bien que se traten de instrucciones parecidas a otras anteriormente ejecutadas.
- Cache Library.
-Data Dictionary Cache.
- Java Pool. Sólo se usa si hemos instalado Java para agilizar el proceso de las instrucciones en ese lenguaje.
Procesos en segundo plano.
Programas en ejecución que realizan las tareas fundamentales sonre la base de datos, entre ellos:
DBWR. Escribe los datos del buffer de cache de la base de datos de la SGA a la base de datos en disco (a los archivos de datos). Eso no ocurre en todo momento, sino cuando se produce un evento de tipo checkpoint. Un checkpoint ocurre cuando se ha consumido un tiempo determinado por el DBA, que se establece para que cada cierto tiempo los datos pasen a grabarse en ficheros de datos y así asegurarles en caso de problemas. El hecho de que esto se haga solo cada cierto tiempo (el tiempo establecido para el checkpoint) se debe a que, de otro modo, el funcionamiento sería muy lento si se accediera más a menudo al disco.
LGWR. Es el proceso que genera escrituras secuenciales en los redo logs (archivos log de rehacer) que son los archivos que guardan la información necesaria para poder recuperar un estado anterior en los datos.
Las instrucciones DML están limitadas por la velocidad de este proceso al guardar los datos. LGWR escribe desde el buffer del caché redo en el SGA hacia los archivos redo en disco.
CKPT. Proceso encargado de comunicar la llegada de un checkpoint, punto de control que ocurre cíclicamente (y que se puede modificar poe el DBA) tras el cual se deben de escribir los datos de memoria a los archivos de datos.
SMON. System Monitor. Proceso encargado de monitorizar el sistema para que funcione correctamente tras un error grave. Además se encarga de la optimización del sistema mejorando el espacio en disco y elimando definitivamente (mediante rollbacks) datos irrecuperables.
PMON. Process Monitor. Se encarga de la comunicación con la PGA y especialmente con el proceso servidor para manejar la conexión con el cliente, eliminado transacciones de usuarios erróneas (por desconexión por ejemplo) y liberando la memoria que se reservó para los usuarios.
ARCn. Proceso de archivado de los archivos Redo. Sirve para que esos datos siempre estén disponibles. Sólo funciona en modo ARCHIVELOG de la base de datos, se explica más adelante.
PGA.
La Program Globasl Area o área global de programa, es la memoria que se reserva por cada usuario para almacenar los datos necesarios para la conexión de un usuario con la base de datos.
Cada conexión tiene su propia PGA con los datos a los que accede el proceso servidor. Entre los datos que almacena están:
La información sobre la sesión con el cliente.
El estado de procesamiento de la instrucción SQL actual.
Datos de caché para acelerar algunas instrucciones SQL (como por ejemplo índices temporales).
Proceso servidor y proceso cliente.
El proceso cliente es el programa en la memoria de la máquina en la que el usuario ha conectado con Oracle. Este proceso se comunica con un proceso servidor que es lanzado cuando el cliente establece conexión con Oracle.
Puede haber un mismo proceso servidor para más de un cliente en caso de una configuración compartida de proceso servidor. Cuando el proceso cliente y el servidor establecen conexión, se crea la sesión de usuario, que es manejada por el proceso servidor. El proceso de usuario no puede acceder directamente a la base de datos.

2.1.2 Estructuras físicas de la base de datos.
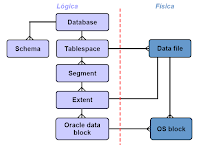
En una base de datos almacenamos información relevante para nuestro negocio u organización y desde el punto de vista físico, la base de datos está conformada por dos tipos de archivos:
- Archivos de datos: contiene los datos de la base de datos internamente, está compuesto por páginas enumeradas secuencialmente que representa la unidad mínima de almacenamiento. Cada página tiene un tamaño de 8kb de información. Existen diferentes tipos de páginas, a tener en cuenta:
- Páginas de datos: es el tipo principal de páginas y son las que almacenan los registros de datos.
- Páginas de espacio libre (PFS Page Free Space): almacenan información sobre la ubicación y el tamaño del espacio libre.
- Paginas GAM and SGAM: utilizadas para ubicar extensiones.
- Páginas de Mapa de Ubicaciones de índices (IAM – Index Allocation Map): contiene información sobre el almacenamiento de páginas de una tabla o índice en particular.
- Páginas Índices: Utilizada para almacenar registros de índices.
- Archivo de Registro de Transacciones: El propósito principal del registro de transacciones es la recuperación de datos a un momento en el tiempo o complementar una restauración de copia de respaldo completa (full backup). El registro de transacciones no contiene páginas, sino entradas con todos los cambios realizados en la base de datos, como son las modificaciones de datos, modificaciones de la base de datos y eventos de copia de seguridad y restauración. El acceso a datos es secuencial, ya que el registro de transacciones se actualiza en el mismo orden cronológico en el que se hacen las modificaciones. Este archivo no puede ser leído por herramientas de usuario de SQL aunque existen herramientas de terceros que leen este archivo para recuperar los cambios efectuados. Dependiendo de la versión el registro de transacciones se utiliza para otros propósitos como por ejemplo bases de datos espejo (mirror) y transporte remoto de transacciones (log shipping).
Para muchos de los administradores de bases de datos, la imagen anterior representa la parte lógica y la parte física, donde:
- Data File: Los datafiles son los archivos físicos en los que se almacenan los objetos que forman parte de un tablespace. Un datafile pertenece solamente a un tablespace y a una instancia de base de datos. Un tablespace puede estar formado por uno o varios datafiles. Cuando se crea un datafile, se debe indicar su nombre, su ubicación o directorio, el tamaño que va a tener y el tablespace al que va a pertenecer. Además, al crearlos, ocupan ya ese espacio aunque se encuentran totalmente vacíos, es decir, Oracle reserva el espacio para poder ir llenándolo poco a poco con posterioridad. Por supuesto, si no hay sitio suficiente para crear un archivo físico del tamaño indicado, se producirá un error y no se creará dicho archivo.
2.1.3 Requerimientos para instalación de la base de datos.

Antes de instalar cualquier SGBD es necesario conocer los requerimientos de hardware y software, el posible software a desinstalar previamente, verificar el registro de Windows y el entorno del sistema, así como otras características de configuración especializadas como pueden ser la reconfiguración de los servicios TCP/IP y la modificación de los tipos archivos HTML para los diversos navegadores.
Se presenta a continuación una serie de requerimientos mínimos de hardware y software para instalar oracle 11g Express y MySQL estándar versión 5.1. en Windows Seven y Ubuntu 10.
2.1.4 Instalación del software de BD en modo transaccional.
Una base de datos en modo transaccional significa que la BD será capaz de que las operaciones de inserción y actualización se hagan dentro de una transacción, es un componente que procesa información descomponiéndola de forma unitaria en operaciones indivisibles, llamadas transacciones, esto quiere decir que todas las operaciones se realizan o no, si sucede algún error en la operación se omite todo el proceso de modificación de la base de datos, si no sucede ningún error se hacen toda la operación con éxito.
Y depende que base de datos uses para efectuar las operaciones pero, es la misma teoría para cualquier BD.
Una transacción es un conjunto de líneas de un programa que llevan insert o update o delete. Todo aquél software que tiene un log de transacciones (que es la "bitácora" que permite hacer operaciones de commit o rollback), propiamente es un software de BD; aquél que no lo tiene (v.g. D-Base), propiamente no lo es. Todo software de base de datos es transaccional; si el software de la BD no es "transaccional", en realidad NO es un "software" de BD; en todo caso, es un software que emula el funcionamiento de un verdadero software de BD. Cada transacción debe finalizar de forma correcta o incorrecta como una unidad completa. No puede acabar en un estado intermedio.
Se usan las siguientes métodos :
- Begin TRans para iniciar la transacción
- CommitTrans para efectuar los cambios con éxito
- RollbackTrans para deshacer los cambios
Una vez que se sabe la forma de ingresar comandos, es el momento de acceder a una base de datos.
Suponga que en su hogar posee varias mascotas y desea registrar distintos tipos de información sobre ellas. Puede hacerlo si crea tablas para almacenar sus datos e introduce en ellas la información deseada. Entonces, podrá responder una variedad de preguntas acerca de sus mascotas recuperando datos desde las tablas.
Los pasos serían:- Crear una base de datos
- Crear una tabla
- Introducir datos en la tabla
- Recuperar datos desde la tabla de varias maneras
- Emplear múltiples tablas
2.1.5 Variables de Ambiente y archivos importantes para instalación.
Variable: Es un espacio en memoria al cual se le da un nombre Hay variables específicas que se crean al momento de entrar al sistema, pero también hay variables que pueden ser definidas por el usuario. Las variables son una forma de pasar información a los programas al momento de ejecutarlos.
Variables de Ambiente: Se usan para personalizar el entorno en el que se ejecutan los programas y para ejecutar en forma correcta los comandos del shell.
Toman su valor inicial generalmente de un archivo .profile, pero hay veces en que el usuario tiene que modificar los valores de alguna variable de ambiente cuando está tratando de instalar o ejecutar un nuevo programa.
A continuación se comentan las opciones más utilizadas de la sección mysqld (afectan al funcionamiento del servidor MySQL), se almacenan en el archivo my.cnf (o my.ini)
Toman su valor inicial generalmente de un archivo .profile, pero hay veces en que el usuario tiene que modificar los valores de alguna variable de ambiente cuando está tratando de instalar o ejecutar un nuevo programa.
A continuación se comentan las opciones más utilizadas de la sección mysqld (afectan al funcionamiento del servidor MySQL), se almacenan en el archivo my.cnf (o my.ini)
basedir = ruta: Ruta a la raíz MySQLconsole: Muestra los errores por consola independientemente de lo que se configure para log_error.
datadir = ruta: Ruta al directorio de datos.
default-table-type = tipo: Tipo de la Tabla InnoDB o, MyISAM.
flush: Graba en disco todos los comandos SQL que se ejecuten (modo de trabajo, sin transacción).
general-log = valor: Con valor uno, permite que funcione el archivo LOG para almacenar las consultas realizadas.
general-log-file = ruta: Indica la ruta al registro general de consultas.
language: Especifica el idioma de los lenguajes de error, normalmente esots archivos de lenguaje, están bajo /usr/local/share.
log-error = ruta: Permite indicar la ruta al registro de errores.
log = ruta: Indica la ruta al registro de consultas.
long-query-time = n: Segundos a partir de los cuales una consulta que tardes más, se considerará una consulta lenta.
og-bin = ruta: Permite indicar la ruta al registro binario.
pid-file = ruta: Ruta al archivo que almacena el identificador de proceso de MySQL.
port = puerto: Puerto de escucha de MySQL.
skip-grant-tables: Entra al servidor saltándose las tablas de permisos, es decir todo el mundo tiene privilegios absolutos.
skip-networking: El acceso a MySQL se hará solo desde el servidor local.
slow-query-log = 0|1: Indica si se hace LOG de las consultas lentas.
slow-query-log-file = ruta: Ruta al archivo que hace LOG de las consultas lentas.
socket = ruta: Archivo o nombre de socket a usar en las conexiones locales.
standalone: Para Windows, hace que el servidor no pase a ser un servicio.
user = usuario: Indica el nombre de usuario con el que se iniciará sesión en MySQL.
tmpdir = ruta: Ruta al directorio para archivos temporales.
Archivos LOG en MySQL
Hay cuatro registros (logs):
1.- Registro de Errores (Error Log): Indica cuando arrancó y se detuvo el servidor. Se graba por defecto en la carpeta de datos de MySQL (archivo host_name.err, donde host_name es el nombre del servidor), pero la variable de sistema log_error permite indicar otra ruta si fuera necesario.
2.- Registro General de Consultas (General Log File): Está en la carpeta de datos de MySQL, salvo que se indique la variable general-log-file. Contiene las consultas realizadas. Es el archivo host_name.log.
3.- Registro Binario (Binary Log): Registra instrucciones DML. Los archivos binarios se almacenan por defecto en el directorio de datos. Sirve para intentar restaurar una base de datos en caso de desastre. Es binario, por lo que su manejo es complicado, para ver el contenido se usa la utilidad mysqlbinlog de esta forma: mysqlbinlog archivoLOG
4.- Registro de Consultas Lentas (Slow Query Log File): Registra las consultas que tardaron más del tiempo mínimo establecido. El archivo está (salvo quese especifique slow-log-file como parámetro) en la carpeta de datos de MySQL con el nombre host_name-slow.log
Hay cuatro registros (logs):
1.- Registro de Errores (Error Log): Indica cuando arrancó y se detuvo el servidor. Se graba por defecto en la carpeta de datos de MySQL (archivo host_name.err, donde host_name es el nombre del servidor), pero la variable de sistema log_error permite indicar otra ruta si fuera necesario.
2.- Registro General de Consultas (General Log File): Está en la carpeta de datos de MySQL, salvo que se indique la variable general-log-file. Contiene las consultas realizadas. Es el archivo host_name.log.
3.- Registro Binario (Binary Log): Registra instrucciones DML. Los archivos binarios se almacenan por defecto en el directorio de datos. Sirve para intentar restaurar una base de datos en caso de desastre. Es binario, por lo que su manejo es complicado, para ver el contenido se usa la utilidad mysqlbinlog de esta forma: mysqlbinlog archivoLOG
4.- Registro de Consultas Lentas (Slow Query Log File): Registra las consultas que tardaron más del tiempo mínimo establecido. El archivo está (salvo quese especifique slow-log-file como parámetro) en la carpeta de datos de MySQL con el nombre host_name-slow.log
2.1.6 Procedimiento general de instalación.
MySQL Enterprise Edition.
MySQL Enterprise Edition incluye el conjunto más completo de características avanzadas y herramientas de gestión para alcanzar los más altos niveles de escalabilidad, seguridad, fiabilidad y tiempo de actividad. Reduce el riesgo, costo y complejidad en el desarrollo, implementación y administración de aplicaciones críticas de negocio MySQL.
MySQL Enterprise Edition incluye el conjunto más completo de características avanzadas y herramientas de gestión para alcanzar los más altos niveles de escalabilidad, seguridad, fiabilidad y tiempo de actividad. Reduce el riesgo, costo y complejidad en el desarrollo, implementación y administración de aplicaciones críticas de negocio MySQL.
El MySQL Enterprise incluye las siguientes opciones:
- Backup: Realiza copias de seguridad de bases de datos MySQL en línea, de los subconjuntos de tablas InnoDB, y la recuperación mediante puntos de restauración.
- Alta Disponibilidad: es proporcionada con soluciones certificadas que incluyen replicación de MySQL.
- Escalabilidad: permite alcanzar el rendimiento sostenido y la escalabilidad de cada vez mayor de usuarios, consulta, y las cargas de datos.
- MySQL Enterprise Security: Proporciona listas para utilizar los módulos de autenticación externos para integrar fácilmente las infraestructuras existentes de seguridad, incluyendo Pluggable Authentication Modules y el directorio activo de Windows.
- MySQL Enterprise Monitor: supervisa continuamente su base de datos y de forma proactiva le asesora sobre cómo implementar las mejores prácticas de MySQL, incluyendo consejos y alertas de seguridad
- MySQL Query Analyzer: Mejora el rendimiento de las aplicaciones mediante el control de rendimiento de las consultas y precisa localización de código SQL que está causando una desaceleración
- MySQL Workbench: Cuenta con ofertas de modelado de datos, desarrollo de SQL y herramientas de administración integral para la administración del servidor de configuración del usuario, y mucho más.
- Backup: Realiza copias de seguridad de bases de datos MySQL en línea, de los subconjuntos de tablas InnoDB, y la recuperación mediante puntos de restauración.
- Alta Disponibilidad: es proporcionada con soluciones certificadas que incluyen replicación de MySQL.
- Escalabilidad: permite alcanzar el rendimiento sostenido y la escalabilidad de cada vez mayor de usuarios, consulta, y las cargas de datos.
- MySQL Enterprise Security: Proporciona listas para utilizar los módulos de autenticación externos para integrar fácilmente las infraestructuras existentes de seguridad, incluyendo Pluggable Authentication Modules y el directorio activo de Windows.
- MySQL Enterprise Monitor: supervisa continuamente su base de datos y de forma proactiva le asesora sobre cómo implementar las mejores prácticas de MySQL, incluyendo consejos y alertas de seguridad
- MySQL Query Analyzer: Mejora el rendimiento de las aplicaciones mediante el control de rendimiento de las consultas y precisa localización de código SQL que está causando una desaceleración
- MySQL Workbench: Cuenta con ofertas de modelado de datos, desarrollo de SQL y herramientas de administración integral para la administración del servidor de configuración del usuario, y mucho más.
El proceso de instalación es muy simple y prácticamente no requiere intervención por parte del usuario.
Comienza el proceso; sólo nos llevará un par de minutos…
Comienza el proceso; sólo nos llevará un par de minutos…

Cada vez que veo la pantalla de la GNU GPL me lleno de felicidad. No sólo por las condiciones y el precio: es además, para mí, una garantía de profesionalidad.

Estadísticamente, la instalación típica será la que mejor se adapte a tus necesidades.

Todo listo; presiona Install cuando quieras.

Una vez instalado MySQL, la siguiente fase es la configuración del servidor en sí mismo. Asegúrate de que la marca Launch the MySQL Instance Configuration Wizard esté activa.

2.1.7 Procedimiento para configuración de un DBMS.
Para configurar nuestro DBMS podemos acceder a las siguientes pantallas, para Oracle o MySQL.El esquema de una base de datos (en inglés, Database Schema) describe la estructura de una Base de datos, en un lenguaje formal soportado por un Sistema administrador de Base de datos (DBMS). En una Base de datos Relacional, el Esquema define sus tablas, sus campos en cada tabla y las relaciones entre cada campo y cada tabla.
Oracle generalmente asocia un 'username' como esquemas en este caso SYSTEM y HR (Recursos humanos).
Por otro lado MySQL presenta dos esquemas information_schema y MySQL ambos guardan información sobre privilegios y procedimientos del gestor y no deben ser eliminados.
Adelante, sin miedo…

Optamos por Detailed Configuration, de modo que se optimice la configuración del servidorMySQL.

Ha llegado un momento crucial. Dependiendo del uso que vayamos a darle a nuestro servidor deberemos elegir una opción u otra, cada una con sus propios requerimientos de memoria. Puede que te guste la opción Developer Machine, para desarrolladores, la más apta para un uso de propósito general y la que menos recursos consume. Si vas a compartir servicios en esta máquina, probablemente Server Machine sea tu elección o, si vas a dedicarla exclusivamente como servidor SQL, puedes optar por Dedicated MySQL Server Machine, pues no te importará asignar la totalidad de los recursos a esta función.

De nuevo, para un uso de propósito general, te recomiendo la opción por defecto, Multifunctional Database.

InnoDB es el motor subyacente que dota de toda la potencia y seguridad a MySQL. Su funcionamiento requiere de unas tablas e índices cuya ubicación puedes configurar. Sin causas de fuerza mayor, acepta la opción por defecto.

Esta pantalla nos permite optimizar el funcionamiento del servidor en previsión del número de usos concurrentes. La opción por defecto, Decision Support (DSS) / OLAP será probablemente la que más te convenga.

Deja ambas opciones marcadas, tal como vienen por defecto. Es la más adecuada para un uso de propósito general o de aprendizaje, tanto si eres desarrollador como no. Aceptar conexiones TCP te permitirá conectarte al servidor desde otras máquinas (o desde la misma simulando un acceso web típico).

Hora de decidir qué codificación de caracteres emplearás, salvo que quieras empezar a trabajar con Unicode porque necesites soporte multilenguaje, probablemente Latin1 te sirva (opción por defecto).

Instalamos MySQL como un servicio de Windows (la opción más limpia) y lo marcamos para que el motor de la base de datos arranque por defecto y esté siempre a nuestra disposición. La alternativa es hacer esto manualmente.
Además, me aseguro de marcar que los ejecutables estén en la variable PATH, para poder invocar a MySQL desde cualquier lugar en la línea de comandos.

Pon una contraseña al usuario root. Esto siempre es lo más seguro.
Si lo deseas, puedes indicar que el usuario root pueda acceder desde una máquina diferente a esta, aunque debo advertirte de que eso tal vez no sea una buena práctica de seguridad.

Última etapa, listos para generar el fichero de configuración y arrancar el servicio.

Sólo damos al botón de Finalizar y terminamos con la configuración del DBMS.

2.1.8 comandos generales de alta y baja del DBMS.
Una tabla es un sistema de elementos de datos (atributo - valores) que se organizan que usando un modelo vertical - columnas (que son identificados por su nombre)- y horizontal filas. Una tabla tiene un número específico de columnas, pero puede tener cualquier número de filas. Cada fila es identificada por los valores que aparecen en un subconjunto particular de la columna que se ha identificado por una llave primaria.
Una tabla de una base de datos es similar en apariencia a una hoja de cálculo, en cuanto a que los datos se almacenan en filas y columnas. Como consecuencia, normalmente es bastante fácil importar una hoja de cálculo en una tabla de una base de datos. La principal diferencia entre almacenar los datos en una hoja de cálculo y hacerlo en una base de datos es la forma de organizarse los datos.
MySQL: Soporta varios motores de almacenamiento que tratan con distintos tipos de tabla. Los motores de almacenamiento de MySQL incluyen algunos que tratan con tablas transaccionales y otros que no lo hacen:
MyISAM: trata tablas no transaccionales. Proporciona almacenamiento y recuperación de datos rápida, así como posibilidad de búsquedas fulltext. MyISAM se soporta en todas las configuraciones
MySQL, y es el motor de almacenamiento por defecto a no ser que tenga una configuración distinta a la que viene por defecto con MySQL.
El motor de almacenamiento MEMORY proporciona tablas en memoria. El motor de almacenamiento MERGE permite una colección de tablas MyISAM idénticas ser tratadas como una simple tabla. Como MyISAM, los motores de almacenamiento MEMORY y MERGE tratan tablas no transaccionales y ambos se incluyen en MySQL por defecto.
Una tabla de una base de datos es similar en apariencia a una hoja de cálculo, en cuanto a que los datos se almacenan en filas y columnas. Como consecuencia, normalmente es bastante fácil importar una hoja de cálculo en una tabla de una base de datos. La principal diferencia entre almacenar los datos en una hoja de cálculo y hacerlo en una base de datos es la forma de organizarse los datos.
MySQL: Soporta varios motores de almacenamiento que tratan con distintos tipos de tabla. Los motores de almacenamiento de MySQL incluyen algunos que tratan con tablas transaccionales y otros que no lo hacen:
MyISAM: trata tablas no transaccionales. Proporciona almacenamiento y recuperación de datos rápida, así como posibilidad de búsquedas fulltext. MyISAM se soporta en todas las configuraciones
MySQL, y es el motor de almacenamiento por defecto a no ser que tenga una configuración distinta a la que viene por defecto con MySQL.
El motor de almacenamiento MEMORY proporciona tablas en memoria. El motor de almacenamiento MERGE permite una colección de tablas MyISAM idénticas ser tratadas como una simple tabla. Como MyISAM, los motores de almacenamiento MEMORY y MERGE tratan tablas no transaccionales y ambos se incluyen en MySQL por defecto.
Los motores de almacenamiento InnoDB y BDB proporcionan tablas transaccionales. BDB se incluye en la distribución binaria MySQL-Max en aquellos sistemas operativos que la soportan. InnoDB también se incluye por defecto en todas las distribuciones binarias de MySQL 5.0. En distribuciones fuente, puede activar o desactivar estos motores de almacenamiento configurando MySQL a su gusto.
El motor de almacenamiento EXAMPLE es un motor de almacenamiento 'tonto' que no hace nada. Puede crear tablas con este motor, pero no puede almacenar datos ni recuperarlos. El objetivo es que sirva como ejemplo en el código MySQL para ilustrar cómo escribir un motor de almacenamiento. Como tal, su interés primario es para desarrolladores.
NDB Cluster es el motor de almacenamiento usado por MySQL Cluster para implementar tablas que se particionan en varias máquinas. Está disponible en distribuciones binarias MySQL-Max 5.0. Este motor de almacenamiento está disponible para Linux, Solaris, y Mac OS X. Los autores mencionan que se añadirá soporte para este motor de almacenamiento en otras plataformas, incluyendo Windows en próximas versiones.
El motor de almacenamiento ARCHIVE se usa para guardar grandes cantidades de datos sin índices con una huella muy pequeña.
El motor de almacenamiento EXAMPLE es un motor de almacenamiento 'tonto' que no hace nada. Puede crear tablas con este motor, pero no puede almacenar datos ni recuperarlos. El objetivo es que sirva como ejemplo en el código MySQL para ilustrar cómo escribir un motor de almacenamiento. Como tal, su interés primario es para desarrolladores.
NDB Cluster es el motor de almacenamiento usado por MySQL Cluster para implementar tablas que se particionan en varias máquinas. Está disponible en distribuciones binarias MySQL-Max 5.0. Este motor de almacenamiento está disponible para Linux, Solaris, y Mac OS X. Los autores mencionan que se añadirá soporte para este motor de almacenamiento en otras plataformas, incluyendo Windows en próximas versiones.
El motor de almacenamiento ARCHIVE se usa para guardar grandes cantidades de datos sin índices con una huella muy pequeña.
El motor de almacenamiento CSV guarda datos en archivos de texto usando formato de valores separados por comas.
El motor de almacenamiento FEDERATED se añadió en MySQL 5.0.3. Este motor guarda datos en una base de datos remota. En esta versión sólo funciona con MySQL a través de la API MySQL C Client. En futuras versiones, será capaz de conectar con otras fuentes de datos usando otros drivers o métodos de conexión clientes.
La versión 5 de MySQL crea por defecto tablas InnoDB que permiten el manejo de integridad referencial, transacciones. Al igual que las tablas regulares de Oracle. Para saber si el gestor de base de datos de MySQL que tenemos las soporta es necesario ejecutar la siguiente sentencia.
SHOW VARIABLES like '%innodb%';
El motor de almacenamiento FEDERATED se añadió en MySQL 5.0.3. Este motor guarda datos en una base de datos remota. En esta versión sólo funciona con MySQL a través de la API MySQL C Client. En futuras versiones, será capaz de conectar con otras fuentes de datos usando otros drivers o métodos de conexión clientes.
La versión 5 de MySQL crea por defecto tablas InnoDB que permiten el manejo de integridad referencial, transacciones. Al igual que las tablas regulares de Oracle. Para saber si el gestor de base de datos de MySQL que tenemos las soporta es necesario ejecutar la siguiente sentencia.
SHOW VARIABLES like '%innodb%';
Comando Describe
MySQL proporciona este comando que resulta útil para conocer la estructura de una tabla, las columnas que la forman y su tipo y restricciones. La sintaxis es la siguiente:
DESCRIBE nombre Tabla.
DESCRIBE f1;
MySQL proporciona este comando que resulta útil para conocer la estructura de una tabla, las columnas que la forman y su tipo y restricciones. La sintaxis es la siguiente:
DESCRIBE nombre Tabla.
DESCRIBE f1;
Comando SHOW TABLES y SHOW CREATE TABLE
El comando SHOW TABLES muestra las tablas dentro de una base de datos y SHOW CREATE TABLES muestra la estructura de creación de la tabla.
Tablas TemporalesLas tablas temporales solo existen mientras la sesión está viva. Si se corre este código en un script de PHP (Cualquier otro lenguaje), la tabla temporal se destruirá automáticamente al término de la ejecución de la página. Si no específica MEMORY, la tabla se guardará por defecto en el disco.
CREATE TEMPORARY TABLE temporal ( Ife INTEGER (13) PRIMARY KEY, Nombre CHAR (30) NOT NULL UNIQUE);
El comando SHOW TABLES muestra las tablas dentro de una base de datos y SHOW CREATE TABLES muestra la estructura de creación de la tabla.
Tablas TemporalesLas tablas temporales solo existen mientras la sesión está viva. Si se corre este código en un script de PHP (Cualquier otro lenguaje), la tabla temporal se destruirá automáticamente al término de la ejecución de la página. Si no específica MEMORY, la tabla se guardará por defecto en el disco.
CREATE TEMPORARY TABLE temporal ( Ife INTEGER (13) PRIMARY KEY, Nombre CHAR (30) NOT NULL UNIQUE);
Este tipo de tabla solo puede ser usada por el usuario que la crea.
Si creamos una tabla que tiene el mismo nombre que una existente en la base de datos, la que existe quedará oculta y trabajaremos sobre la temporal.
Tablas Memory (Head)
Se almacenan en memoria
Una tabla head no puede tener más de 1600 campos
Las tablas MEMORY usan una longitud de registro fija.
MEMORY no soporta columnas BLOB o TEXT.
MEMORY en MySQL 5.0 incluye soporte para columnas AUTO_INCREMENT e índices en columnas que contengan valores NULL.
Las tablas MEMORY se comparten entre todos los clientes (como cualquier otra tabla no-TEMPORARY).
CREATE TEMPORARY TABLE temporal ( Ife INTEGER (13) PRIMARY KEY, Nombre CHAR (30) NOT NULL UNIQUE) ENGINE = MEMORY;
Modificación
Esta operación se puede realizar con el comando ALTER TABLE. Para usar ALTER TABLE, necesita permisos ALTER, INSERT y CREATE para la tabla. La sintaxis para MySQL es
ALTER [IGNORE] TABLE tbl_name
alter_specification [, alter_specification]...;
alter_specification:
ADD [COLUMN] column_definition [FIRST | AFTER col_name]
ADD [COLUMN] (column_definition,)
ADD INDEX [index_name] [index_type] (index_col_name,)
ADD [CONSTRAINT [symbol]]
PRIMARY KEY [index_type] (index_col_name,)
ADD [CONSTRAINT [symbol]]
UNIQUE [index_name] [index_type] (index_col_name,)
ADD [FULLTEXT|SPATIAL] [index_name] (index_col_name,)
ADD [CONSTRAINT [symbol]]
FOREIGN KEY [index_name] (index_col_name,)
[reference_definition]
ALTER [COLUMN] col_name {SET DEFAULT literal | DROP DEFAULT}
CHANGE [COLUMN] old_col_name column_definition
[FIRST|AFTER col_name]
MODIFY [COLUMN] column_definition [FIRST | AFTER col_name]
DROP [COLUMN] col_name
DROP PRIMARY KEY
DROP INDEX index_name
DROP FOREIGN KEY fk_symbol
DISABLE KEYS
ENABLE KEYS
RENAME [TO] new_tbl_name
ORDER BY col_name
CONVERT TO CHARACTER SET charset_name [COLLATE collation_name]
[DEFAULT] CHARACTER SET charset_name [COLLATE collation_name]
DISCARD TABLESPACE
IMPORT TABLESPACE
table_options
Si creamos una tabla que tiene el mismo nombre que una existente en la base de datos, la que existe quedará oculta y trabajaremos sobre la temporal.
Tablas Memory (Head)
Se almacenan en memoria
Una tabla head no puede tener más de 1600 campos
Las tablas MEMORY usan una longitud de registro fija.
MEMORY no soporta columnas BLOB o TEXT.
MEMORY en MySQL 5.0 incluye soporte para columnas AUTO_INCREMENT e índices en columnas que contengan valores NULL.
Las tablas MEMORY se comparten entre todos los clientes (como cualquier otra tabla no-TEMPORARY).
CREATE TEMPORARY TABLE temporal ( Ife INTEGER (13) PRIMARY KEY, Nombre CHAR (30) NOT NULL UNIQUE) ENGINE = MEMORY;
Modificación
Esta operación se puede realizar con el comando ALTER TABLE. Para usar ALTER TABLE, necesita permisos ALTER, INSERT y CREATE para la tabla. La sintaxis para MySQL es
ALTER [IGNORE] TABLE tbl_name
alter_specification [, alter_specification]...;
alter_specification:
ADD [COLUMN] column_definition [FIRST | AFTER col_name]
ADD [COLUMN] (column_definition,)
ADD INDEX [index_name] [index_type] (index_col_name,)
ADD [CONSTRAINT [symbol]]
PRIMARY KEY [index_type] (index_col_name,)
ADD [CONSTRAINT [symbol]]
UNIQUE [index_name] [index_type] (index_col_name,)
ADD [FULLTEXT|SPATIAL] [index_name] (index_col_name,)
ADD [CONSTRAINT [symbol]]
FOREIGN KEY [index_name] (index_col_name,)
[reference_definition]
ALTER [COLUMN] col_name {SET DEFAULT literal | DROP DEFAULT}
CHANGE [COLUMN] old_col_name column_definition
[FIRST|AFTER col_name]
MODIFY [COLUMN] column_definition [FIRST | AFTER col_name]
DROP [COLUMN] col_name
DROP PRIMARY KEY
DROP INDEX index_name
DROP FOREIGN KEY fk_symbol
DISABLE KEYS
ENABLE KEYS
RENAME [TO] new_tbl_name
ORDER BY col_name
CONVERT TO CHARACTER SET charset_name [COLLATE collation_name]
[DEFAULT] CHARACTER SET charset_name [COLLATE collation_name]
DISCARD TABLESPACE
IMPORT TABLESPACE
table_options
Fuentes:



Comentarios
Publicar un comentario